Installation
llmeval is a tool which help establish best practices for organizing prompt templates and running LLM application-level evaluation.
Used together with log10, and your team can make safe changes, evolve and increase the reliability and quality of your LLM application using the Log10 GitHub application.
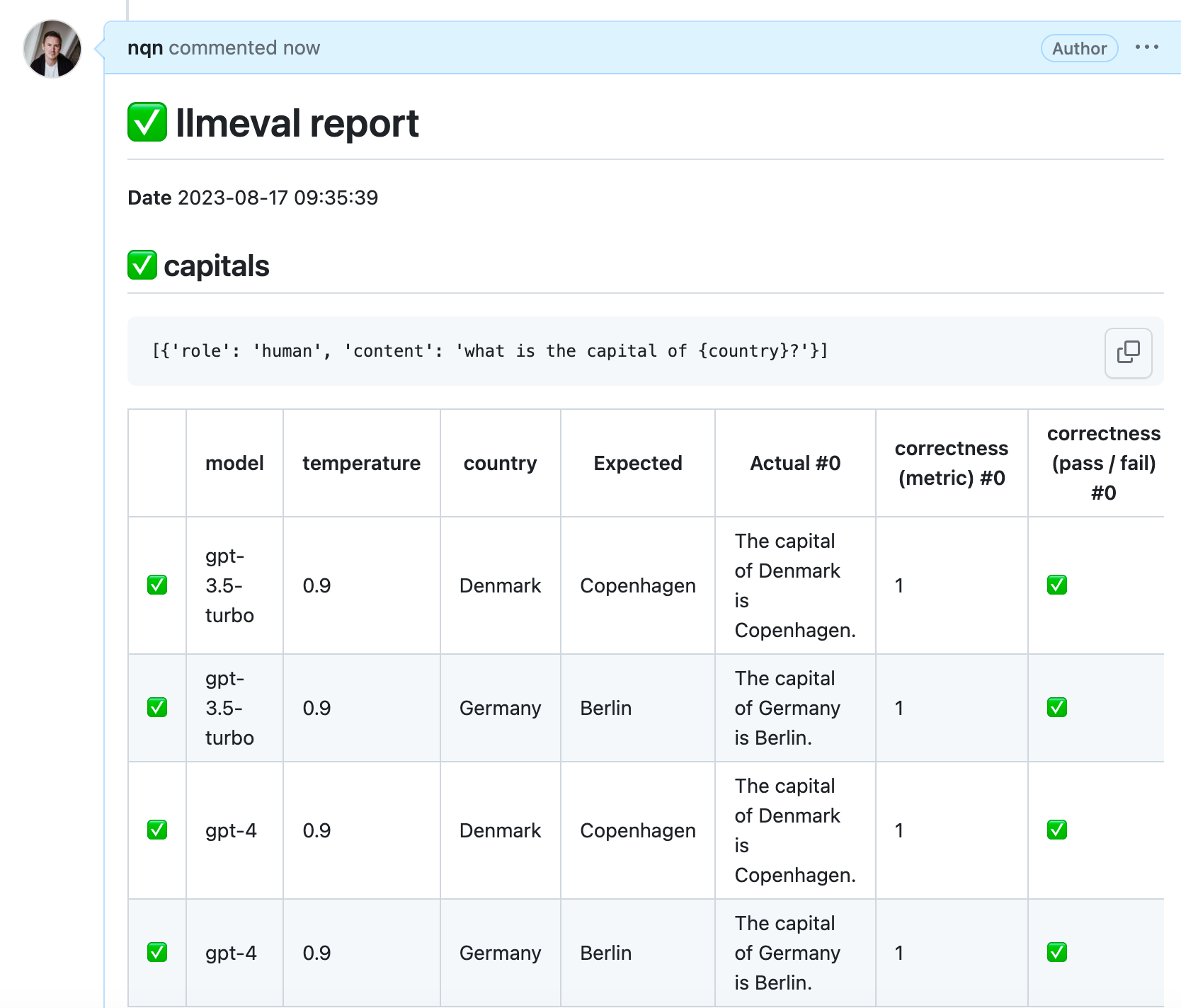
Running llmeval locally
To install llmeval and get your repository set up for evaluation, you can execute the following:
$ cd yourrepo
$ pip install llmeval
$ # Initialize the repository with the expected prompt configuration structure
$ llmeval init
...
$ # Run evaluation
$ llmeval run
...
$ # Check results in markdown reports
$ llmeval reportThis will initialize a prompts directory with a few examples to get started:
- llmeval.yaml
- capitals.yaml
- code.yaml
- grading.yaml
- math.yaml
- summary.yaml
- capitals.yaml
- code.yaml
- grading.yaml
- math.yaml
- summary.yaml
To demonstrate the prompt and test files, let us look at the math example in yourrepo/prompts/math.yaml:
defaults:
- tests/math
name: math
model: gpt-4-16k
temperature: 0.0
variables:
- name: a
- name: b
messages:
- role: "human"
content: "What is {a} + {b}? Only return the answer without any explanation"That the message template can be any number of messages from different roles (human, system or ai).
With a test case looking like this (from yourrepo/prompts/tests/math.yaml):
metrics:
- name: exact_match
code: |
metric = actual == expected
result = metric
references:
- input:
a: 4
b: 4
expected: "8"The metric code is evaluated by a python interpreter, so can be anything from simple comparison (strict, fuzzy, includes etc) or model based evaluation like correctness scores, or custom quality grading (from yourrepo/prompts/capitals.yaml):
metrics:
- name: correctness
code: |
from langchain.evaluation import load_evaluator
evaluator = load_evaluator("labeled_criteria", criteria="correctness")
eval_result = evaluator.evaluate_strings(
input=prompt,
prediction=actual,
reference=expected,
)
metric = eval_result["score"]
result = metric > 0.5
references:
- input:
country: Denmark
expected: Copenhagen
- input:
country: Germany
expected: BerlinIn this case, langchain’s model based evaluator is used to determine the degree of correctness based on the reference expected value. But as you can probably tell, this could be customized quite a bit to fit your criteria for quality, or calling into tools or libraries that you may have.
Using llmeval with GitHub
Alpha release evaluation support is still in alpha. To get setup with the log10 github evaluation flow, please get in touch with us at [email protected]
Install application
Go to the log10 github application (opens in a new tab) and install it on the repository you are working on.

Select repo owner
Select repo
Submit your first PR
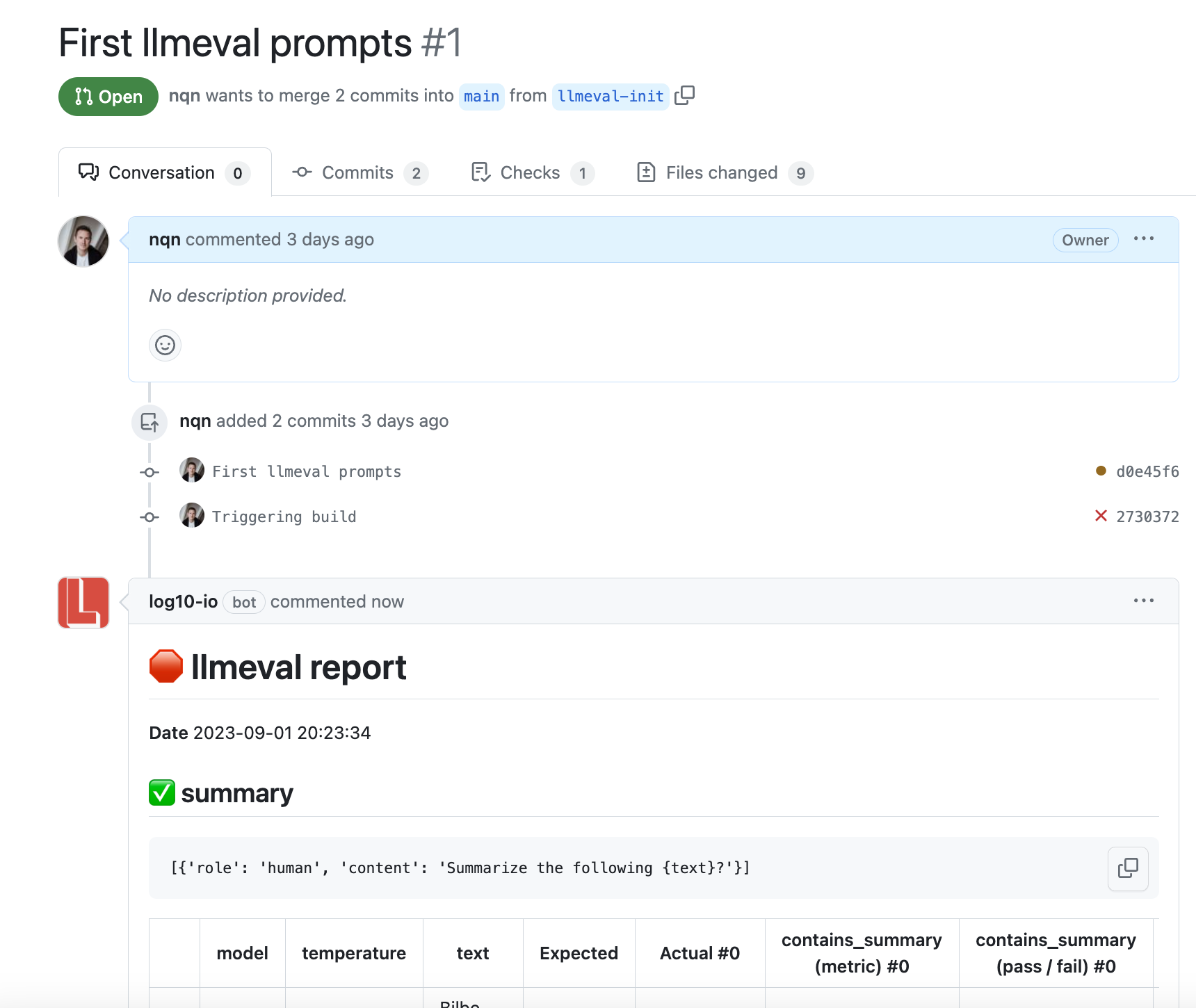
Use git to create a PR (which has been initialized with llmeval init).
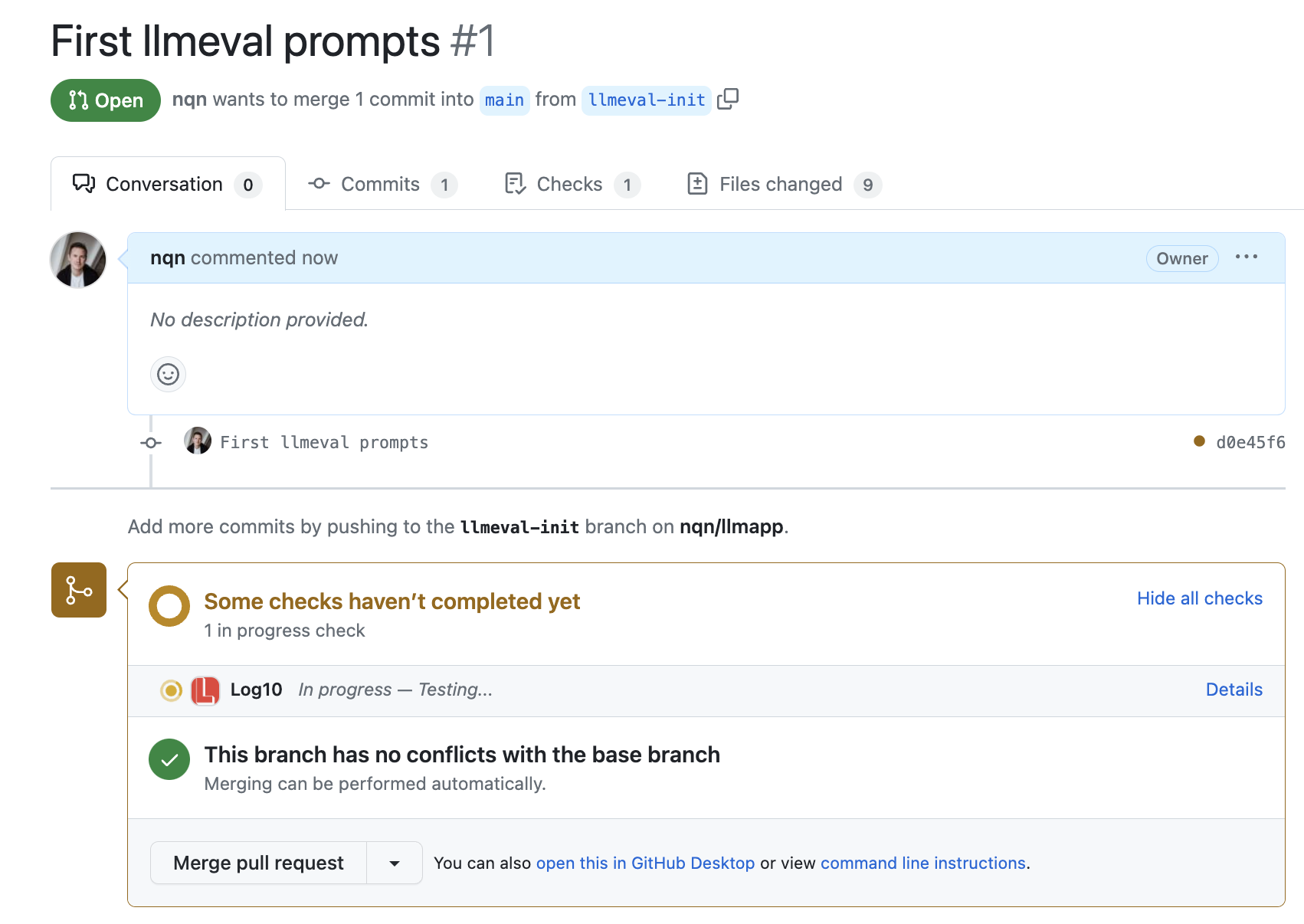
After a few minutes, you should get a report comment and status with the test results.
Next steps
To learn more about the configuration and reports, read more here.
Coming soon
- Comparison to baselines values
- Report history and overview