The best LLM efficiency suite.
Build AI for risk-sensitive domains using evaluation-driven development and a comprehensive accuracy improvement platform that effortlessly scales expert review.
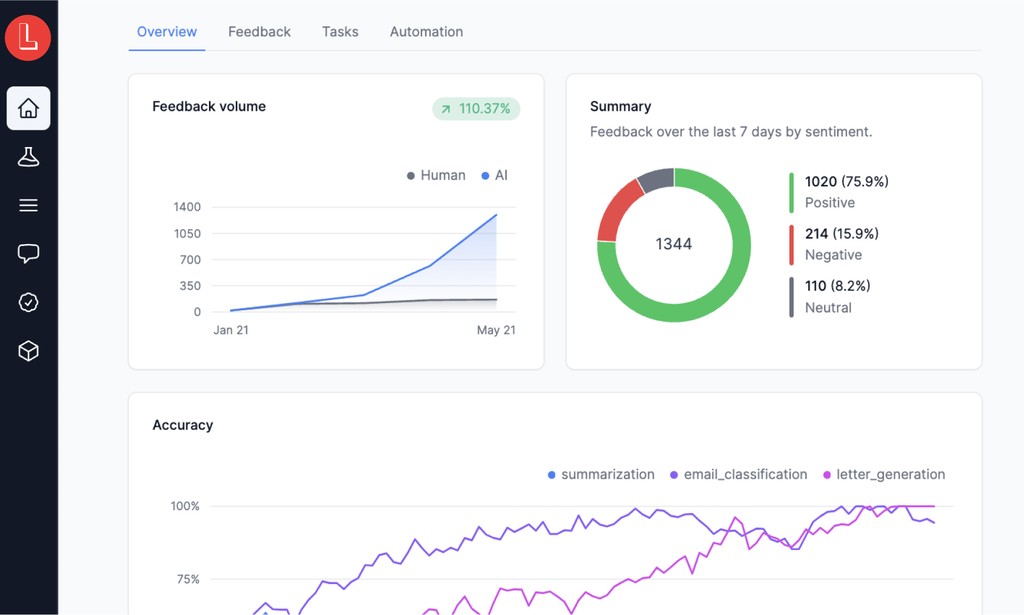
The fast path to AI accuracy
Save massive time
Establish a quality pattern of continuous evaluation during development with a declarative test suite that’s flexible enough to handle complex agents with multiple steps or tool integrations.
Remove LLM blindess
Detect subjective errors and nuances missed by programmatic approaches using domain-specific evaluation models that can be deployed with just a few samples.
Improve product quality
Respond in real time to critical errors. Equip engineers with prioritized workflows and an LLM IDE to fix issues. Fine tune prompt and models using datasets curated with feedback.
Evaluation
Setup an eval-driven workflow in minutes.
Evaluate AI systems from simple applications to complex agents with a flexible, code-based approach built on test frameworks like pytest. Use dashboard insights to analyze and iterate.
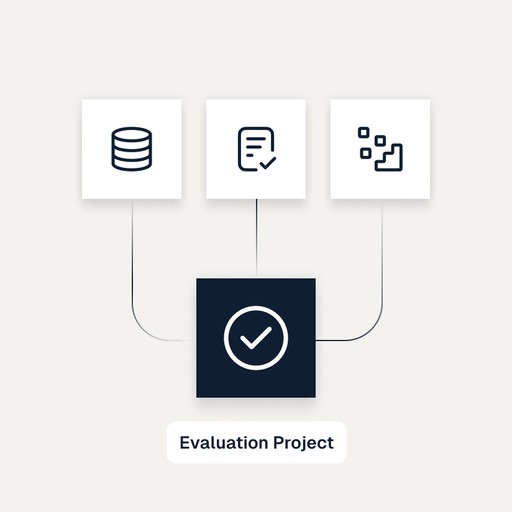
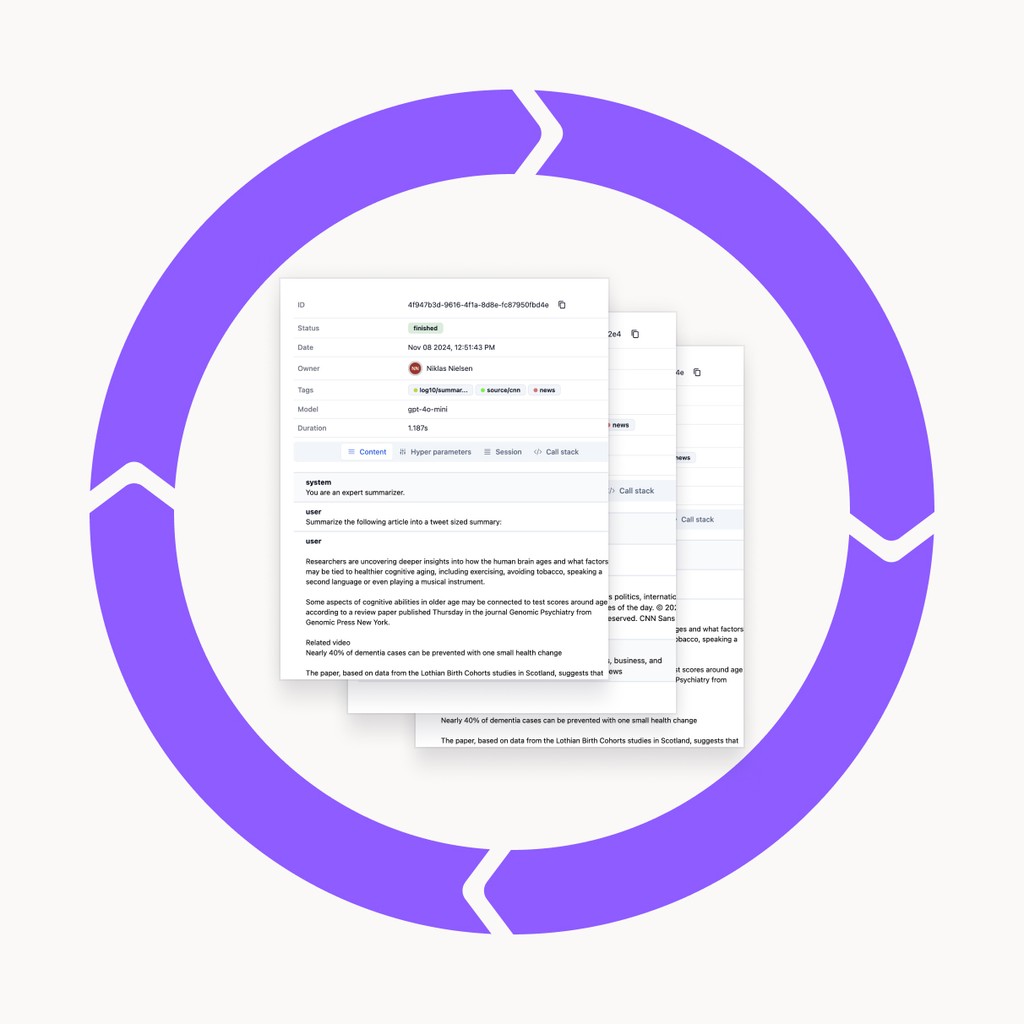
1. Load & Log Your Data
Easily integrate your data for evaluation.
Easily integrate your data for evaluation.
Easily integrate your data for evaluation.
Easily integrate your data for evaluation.
Import your existing files or utilize data already available within the Log10 platform. Automatically log results to capture key performance insights as you test and iterate on your applications.
Import your existing files or utilize data already available within the Log10 platform. Automatically log results to capture key performance insights as you test and iterate on your applications.
Import your existing files or utilize data already available within the Log10 platform. Automatically log results to capture key performance insights as you test and iterate on your applications.
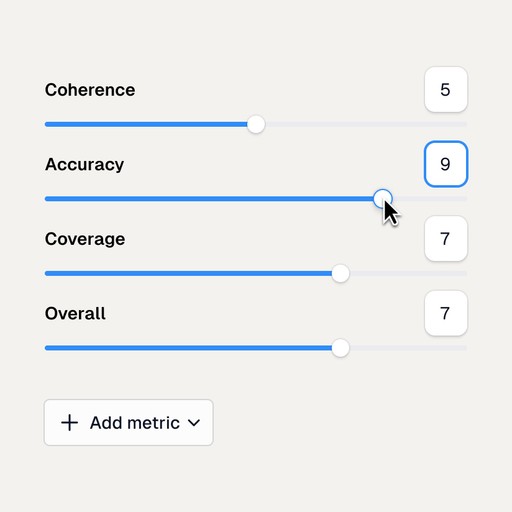
2. Define Metrics & Evaluate
Set metrics and compare outputs.
Set metrics and compare outputs.
Set metrics and compare outputs.
Set metrics and compare outputs.
Define benchmarks using strict or fuzzy matching techniques and incorporate advanced metrics like BLEU and ROUGE. Add AI-based tools such as Log10’s AutoFeedback or LLM-as-a-Judge for nuanced, domain-specific assessment of your AI’s outputs.
Define benchmarks using strict or fuzzy matching techniques and incorporate advanced metrics like BLEU and ROUGE. Add AI-based tools such as Log10’s AutoFeedback or LLM-as-a-Judge for nuanced, domain-specific assessment of your AI’s outputs.
Define benchmarks using strict or fuzzy matching techniques and incorporate advanced metrics like BLEU and ROUGE. Add AI-based tools such as Log10’s AutoFeedback or LLM-as-a-Judge for nuanced, domain-specific assessment of your AI’s outputs.
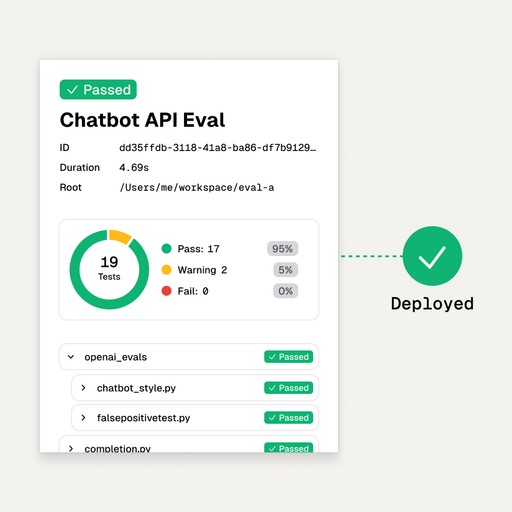
3. Iterate, Log, & Deploy
Refine and deploy with detailed insights.
Refine and deploy with detailed insights.
Refine and deploy with detailed insights.
Refine and deploy with detailed insights.
Analyze performance distribution and reliability through comprehensive summary statistics in your logs. Iterate quickly on feedback to ensure your model consistently meets high standards, then deploy with confidence.
Analyze performance distribution and reliability through comprehensive summary statistics in your logs. Iterate quickly on feedback to ensure your model consistently meets high standards, then deploy with confidence.
Analyze performance distribution and reliability through comprehensive summary statistics in your logs. Iterate quickly on feedback to ensure your model consistently meets high standards, then deploy with confidence.
“Log10 is a critical part of our stack – we could not have scaled LLM accuracy without them.”
“Log10 is a critical part of our stack – we could not have scaled LLM accuracy without them.”
“Log10 is a critical part of our stack – we could not have scaled LLM accuracy without them.”
“Log10 is a critical part of our stack – we could not have scaled LLM accuracy without them.”
Alexander Kvamme, CEO, Echo AI
Alexander Kvamme, CEO, Echo AI
Alexander Kvamme, CEO, Echo AI
Empower your AI with feedback at scale.

Logs & Annotation
Logs & Annotation
Add expert insight.
Leverage human expertise to refine AI performance. Define complex feedback tasks, review LLM completions in a streamlined Inbox, and add valuable insights to your Feedback Stream. Achieve precise, curated feedback for smarter, more accurate outcomes.
Leverage human expertise to refine AI performance. Define complex feedback tasks, review LLM completions in a streamlined Inbox, and add valuable insights to your Feedback Stream. Achieve precise, curated feedback for smarter, more accurate outcomes.
Leverage human expertise to refine AI performance. Define complex feedback tasks, review LLM completions in a streamlined Inbox, and add valuable insights to your Feedback Stream. Achieve precise, curated feedback for smarter, more accurate outcomes.
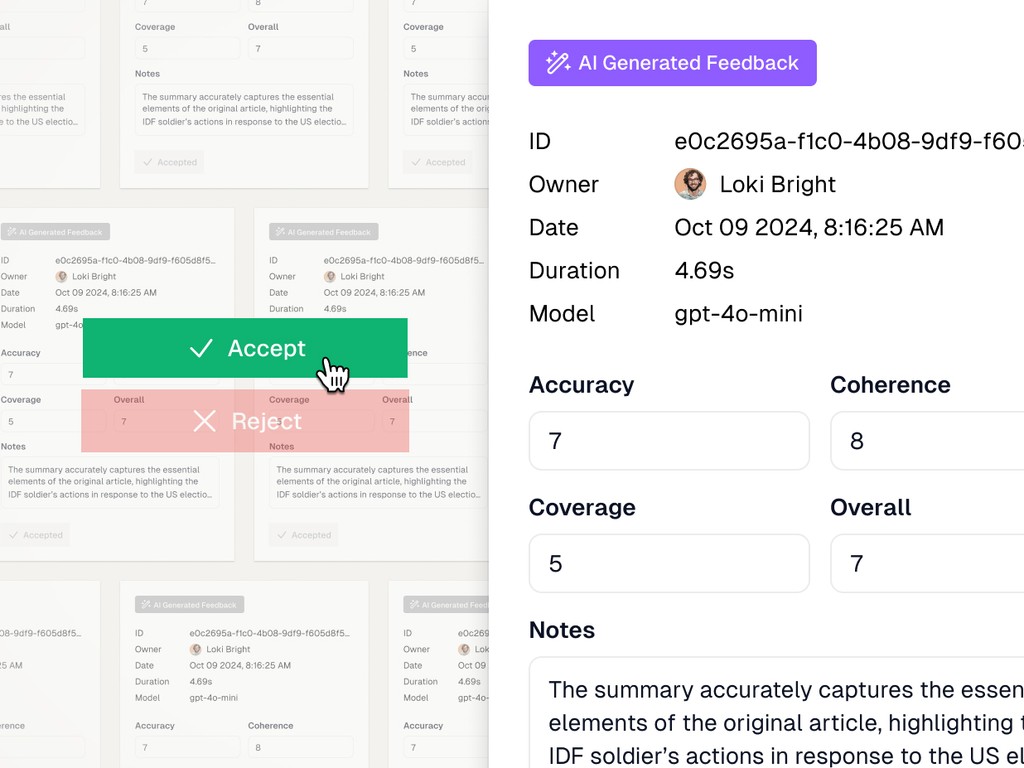
AutoFeedback
AutoFeedback
Scale expert review.
Log10 AutoFeedback combines expert-level precision with the speed of automation, allowing Product Managers and Subject Matter Experts to rapidly assess AI performance with just a few annotated samples. Streamline evaluations, iterate faster, and drive better outcomes—without the need for extensive human review.
Log10 AutoFeedback combines expert-level precision with the speed of automation, allowing Product Managers and Subject Matter Experts to rapidly assess AI performance with just a few annotated samples. Streamline evaluations, iterate faster, and drive better outcomes—without the need for extensive human review.
Log10 AutoFeedback combines expert-level precision with the speed of automation, allowing Product Managers and Subject Matter Experts to rapidly assess AI performance with just a few annotated samples. Streamline evaluations, iterate faster, and drive better outcomes—without the need for extensive human review.
“Log10 gives us the confidence to rapidly iterate and improve our Financial Analyst copilot.”
“Log10 gives us the confidence to rapidly iterate and improve our Financial Analyst copilot.”
“Log10 gives us the confidence to rapidly iterate and improve our Financial Analyst copilot.”
“Log10 gives us the confidence to rapidly iterate and improve our Financial Analyst copilot.”
Michael Struwig, Head of AI, OpenBB
Michael Struwig, Head of AI, OpenBB
Michael Struwig, Head of AI, OpenBB
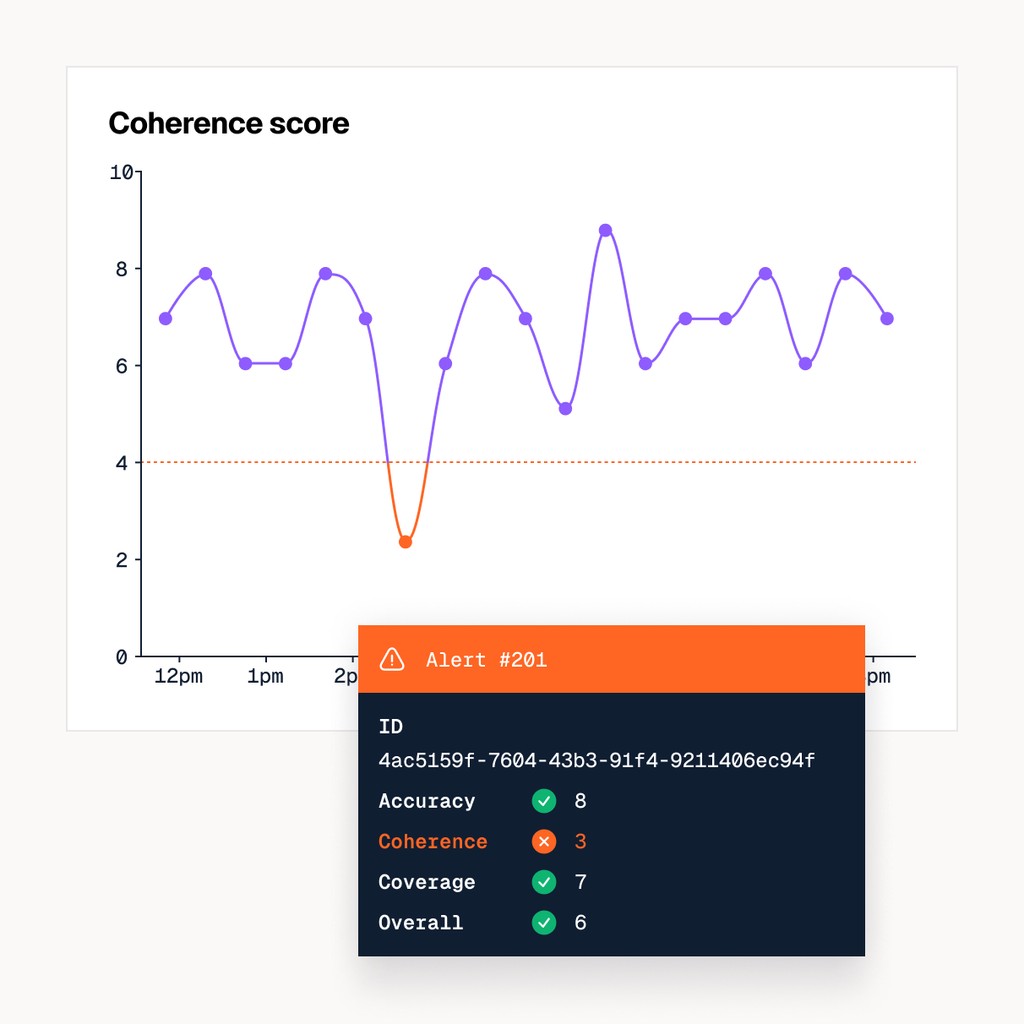
Monitoring & Alerts
Monitoring & Alerts
Detect errors in real time.
Log10 AutoFeedback automatically reviews LLM completions with expert-level precision, creating a real-time accuracy signal that powers monitoring and alerts.
Log10 AutoFeedback automatically reviews LLM completions with expert-level precision, creating a real-time accuracy signal that powers monitoring and alerts.
Log10 AutoFeedback automatically reviews LLM completions with expert-level precision, creating a real-time accuracy signal that powers monitoring and alerts.
Track application performance based on your eval criteria.
Track application performance based on your eval criteria.
Track application performance based on your eval criteria.
Track application performance based on your eval criteria.
Define quality thresholds to serve as guardrails.
Define quality thresholds to serve as guardrails.
Define quality thresholds to serve as guardrails.
Define quality thresholds to serve as guardrails.
Get instant alerts when quality drops below key thresholds.
Get instant alerts when quality drops below key thresholds.
Get instant alerts when quality drops below key thresholds.
Get instant alerts when quality drops below key thresholds.
Respond in real time to critical issues.
Respond in real time to critical issues.
Respond in real time to critical issues.
Respond in real time to critical issues.
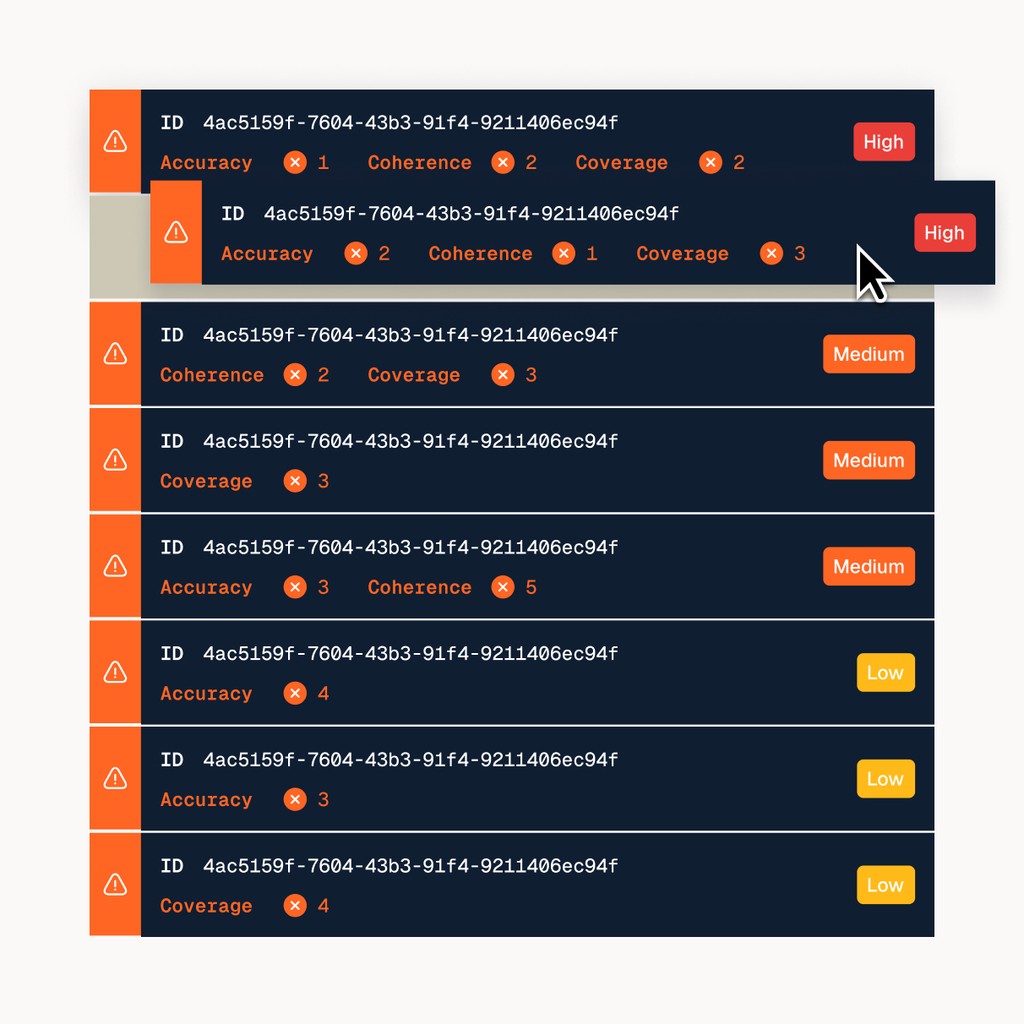
Issue triage
Issue triage
Prioritize the top problems.
With our flexible tagging system and real-time AutoFeedback, you can classify LLM completions based on your specific evaluation criteria, creating a streamlined workflow for engineers to resolve issues quickly.
With our flexible tagging system and real-time AutoFeedback, you can classify LLM completions based on your specific evaluation criteria, creating a streamlined workflow for engineers to resolve issues quickly.
With our flexible tagging system and real-time AutoFeedback, you can classify LLM completions based on your specific evaluation criteria, creating a streamlined workflow for engineers to resolve issues quickly.
Tag completions according to your evaluation criteria.
Tag completions according to your evaluation criteria.
Tag completions according to your evaluation criteria.
Tag completions according to your evaluation criteria.
Generate a prioritized resolution queue.
Generate a prioritized resolution queue.
Generate a prioritized resolution queue.
Generate a prioritized resolution queue.
Quickly resolve issues with the Log10 LLM IDE.
Quickly resolve issues with the Log10 LLM IDE.
Quickly resolve issues with the Log10 LLM IDE.
Quickly resolve issues with the Log10 LLM IDE.

LLM IDE
LLM IDE
Analyze, debug, and improve prompts.
Log10 Playgrounds serve as your LLM IDE for prompt engineering, allowing you to modify and experiment with prompts using new instructions, models, and hyperparameters to achieve better results.
Log10 Playgrounds serve as your LLM IDE for prompt engineering, allowing you to modify and experiment with prompts using new instructions, models, and hyperparameters to achieve better results.
Log10 Playgrounds serve as your LLM IDE for prompt engineering, allowing you to modify and experiment with prompts using new instructions, models, and hyperparameters to achieve better results.
Search logs with precision using full-text, tags, and filters.
Search logs with precision using full-text, tags, and filters.
Search logs with precision using full-text, tags, and filters.
Search logs with precision using full-text, tags, and filters.
Open in collaborative Playgrounds for fast debugging.
Open in collaborative Playgrounds for fast debugging.
Open in collaborative Playgrounds for fast debugging.
Open in collaborative Playgrounds for fast debugging.
Compare prompts across different models.
Compare prompts across different models.
Compare prompts across different models.
Compare prompts across different models.
Optimize prompts with the Log10 AutoPrompt copilot.
Optimize prompts with the Log10 AutoPrompt copilot.
Optimize prompts with the Log10 AutoPrompt copilot.
Optimize prompts with the Log10 AutoPrompt copilot.
Tuning
Tuning
Create a continuous improvement loop.
Collect feedback at scale and fine-tune prompts and models with platform-curated datasets, creating a closed-loop system that tailors general-purpose LLMs to specialized tasks like medical diagnosis or legal analysis.
Collect feedback at scale and fine-tune prompts and models with platform-curated datasets, creating a closed-loop system that tailors general-purpose LLMs to specialized tasks like medical diagnosis or legal analysis.
Collect feedback at scale and fine-tune prompts and models with platform-curated datasets, creating a closed-loop system that tailors general-purpose LLMs to specialized tasks like medical diagnosis or legal analysis.
Enhance datasets with scaled production feedback.
Enhance datasets with scaled production feedback.
Enhance datasets with scaled production feedback.
Enhance datasets with scaled production feedback.
Boost accuracy by fine-tuning models and prompts.
Boost accuracy by fine-tuning models and prompts.
Boost accuracy by fine-tuning models and prompts.
Boost accuracy by fine-tuning models and prompts.
Continuously iterate for ongoing improvement.
Continuously iterate for ongoing improvement.
Continuously iterate for ongoing improvement.
Continuously iterate for ongoing improvement.
Easy Programmatic Integration
Integrate Log10 with a single line of code
Log10 provides powerful Python and JavaScript client libraries with LLM library wrappers, Log10 LLM abstractions, and callback functionality for seamless integration into both new and existing projects. Log10 supports:
Foundational models: OpenAI, Anthropic, Gemini, etc.
Foundational models: OpenAI, Anthropic, Gemini, etc.
Foundational models: OpenAI, Anthropic, Gemini, etc.
Foundational models: OpenAI, Anthropic, Gemini, etc.
Open-source models: Llama, Mistral, etc.
Open-source models: Llama, Mistral, etc.
Open-source models: Llama, Mistral, etc.
Open-source models: Llama, Mistral, etc.
Inference endpoints: Together.AI, MosaicML, etc.
Inference endpoints: Together.AI, MosaicML, etc.
Inference endpoints: Together.AI, MosaicML, etc.
Inference endpoints: Together.AI, MosaicML, etc.
LLM Frameworks: LangChain, LiteLLM, etc.
LLM Frameworks: LangChain, LiteLLM, etc.
LLM Frameworks: LangChain, LiteLLM, etc.
LLM Frameworks: LangChain, LiteLLM, etc.
OpenAI
Llama-3 (self-hosted)
Anthropic
Log10
Langchain
import openai
from log10.load import log10
log10(openai)
client = openai.OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are the most knowledgable Star Wars guru on the planet",
},
{
"role": "user",
"content": "Write the time period of all the Star Wars movies and spinoffs?",
},
],
)
print(completion.choices[0].message)OpenAI
Llama-3 (self-hosted)
Anthropic
Log10
Langchain
import openai
from log10.load import log10
log10(openai)
client = openai.OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are the most knowledgable Star Wars guru on the planet",
},
{
"role": "user",
"content": "Write the time period of all the Star Wars movies and spinoffs?",
},
],
)
print(completion.choices[0].message)OpenAI
Llama-3 (self-hosted)
Anthropic
Log10
Langchain
import openai
from log10.load import log10
log10(openai)
client = openai.OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are the most knowledgable Star Wars guru on the planet",
},
{
"role": "user",
"content": "Write the time period of all the Star Wars movies and spinoffs?",
},
],
)
print(completion.choices[0].message)OpenAI
Llama-3 (self-hosted)
Anthropic
Log10
Langchain
import openai
from log10.load import log10
log10(openai)
client = openai.OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are the most knowledgable Star Wars guru on the planet",
},
{
"role": "user",
"content": "Write the time period of all the Star Wars movies and spinoffs?",
},
],
)
print(completion.choices[0].message)Don’t take it from us.
See how we’ve helped these companies.




Don’t take it from us.
See how we’ve helped these companies.
Don’t take it from us.
See how we’ve helped these companies.
Don’t take it from us.
See how we’ve helped these companies.
Ready to turn your PoCs into profitable AI solutions?

Ready to turn your PoCs into profitable AI solutions?
Ready to turn your PoCs into profitable AI solutions?
Ready to turn your PoCs into profitable AI solutions?



Developers
Solutions
Industries
© Copyright 2024 Log10, Inc. All rights reserved.
Developers
Solutions
Industries
© Copyright 2024 Log10, Inc. All rights reserved.
Developers
Solutions
Industries
© Copyright 2024 Log10, Inc. All rights reserved.
Developers
Solutions
Industries
© Copyright 2024 Log10, Inc. All rights reserved.