Improve your
LLM applications
in productionOptimize LLM applications by tuning prompts and models
AI-powered LLMOps for developers
From development to production across data management, evals & fine-tuning.
- Prompt Engineering Copilot
Use our Prompt Engineering Copilot to get to more accurate prompts faster via AI-powered tuning of prompts and models
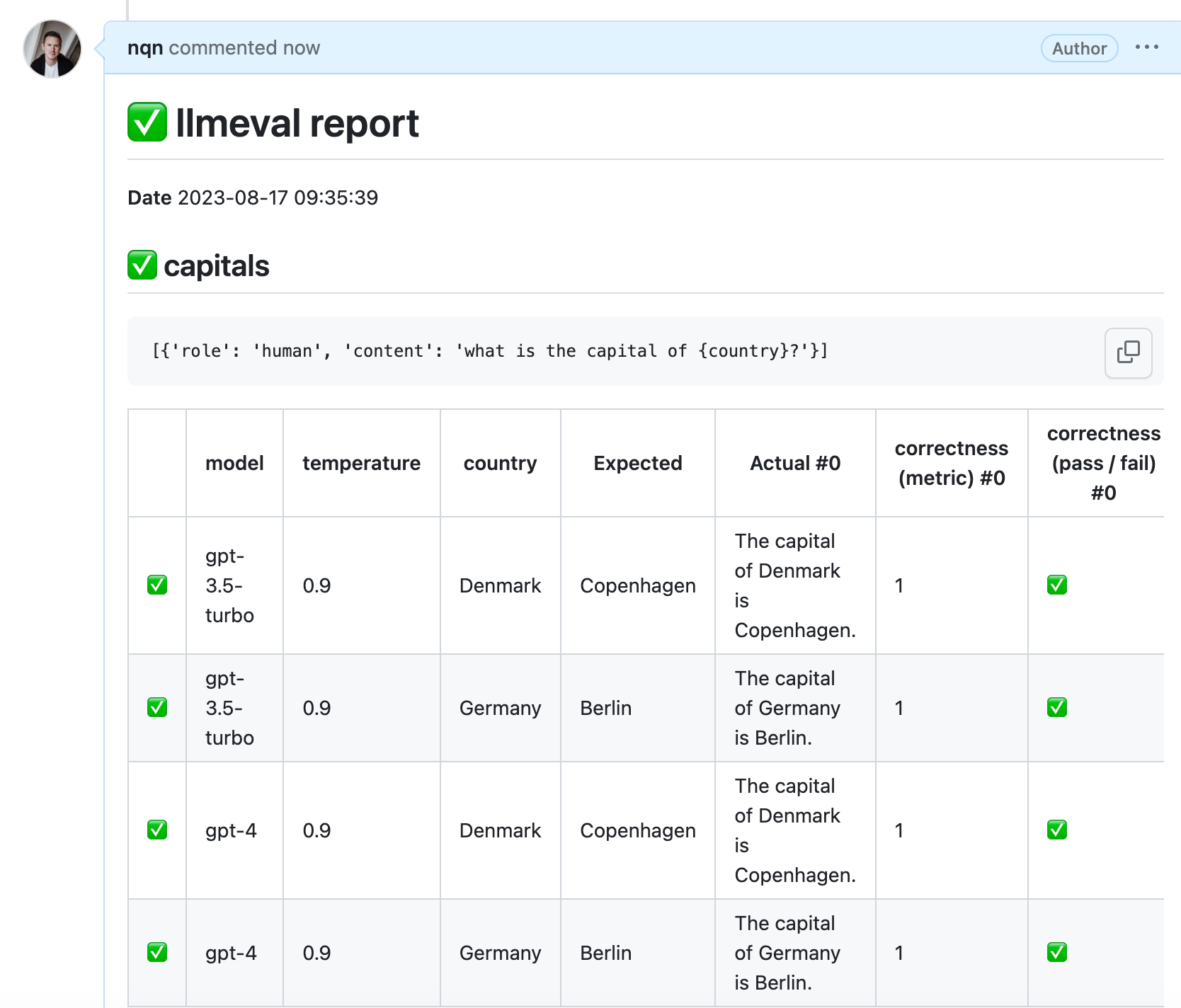
- Evaluate
Integrate Log10's llmeval tool to iterate even faster during development & continuously monitor the accuracy of your LLM apps in production
- AutoFeedback
Scale human review of LLM outputs with the power of Log10's AutoFeedback solution. Read the technical details
Debug, compare and improve prompts & models
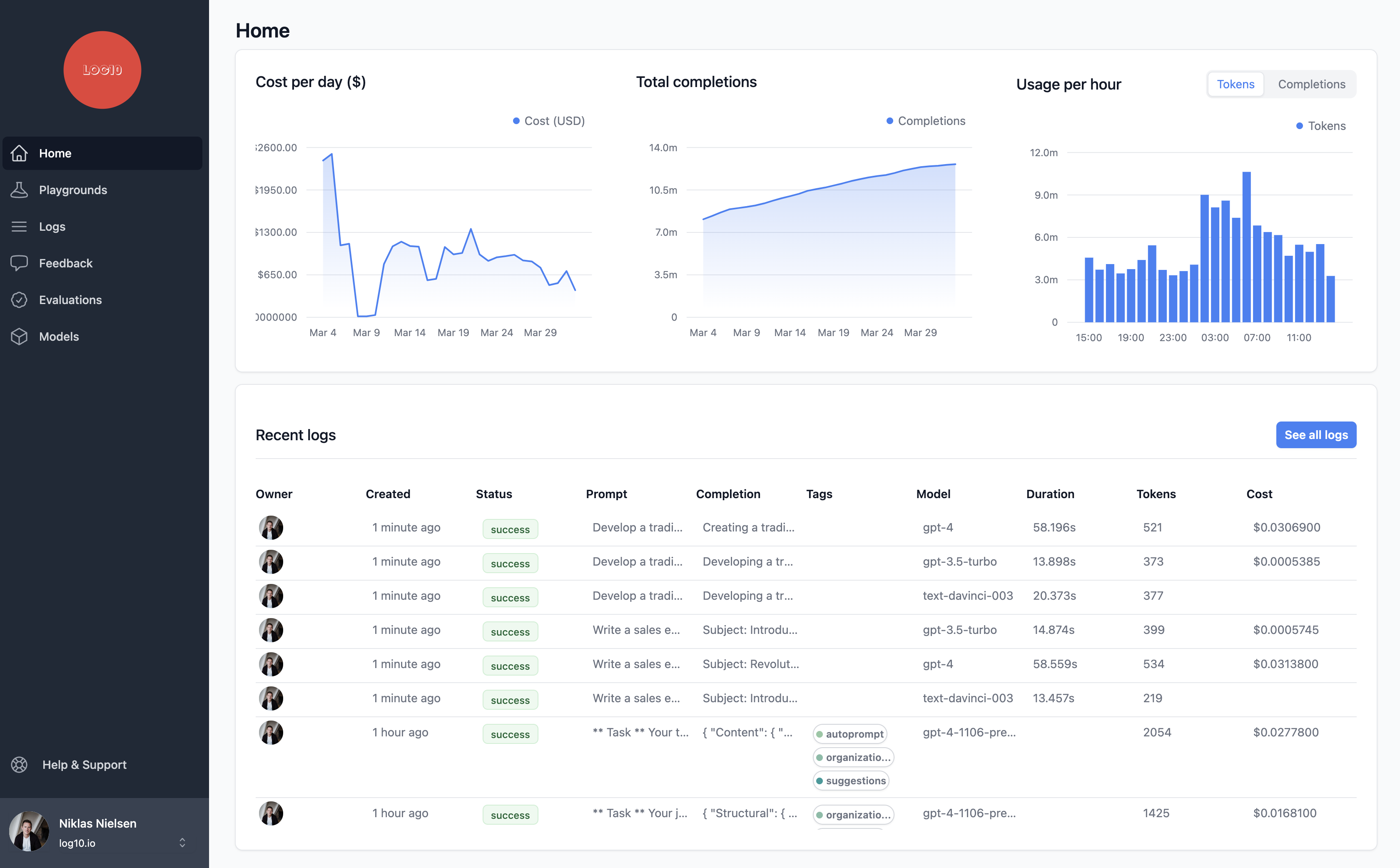
Logs
- Stats
- Get latency, cost & stats for each request
- Feedback
- Collect feedback for model fine-tuning
- Organize
- with full text search, tags and filters
- Create playgrounds from logs
- improve accuracy with new prompts and models
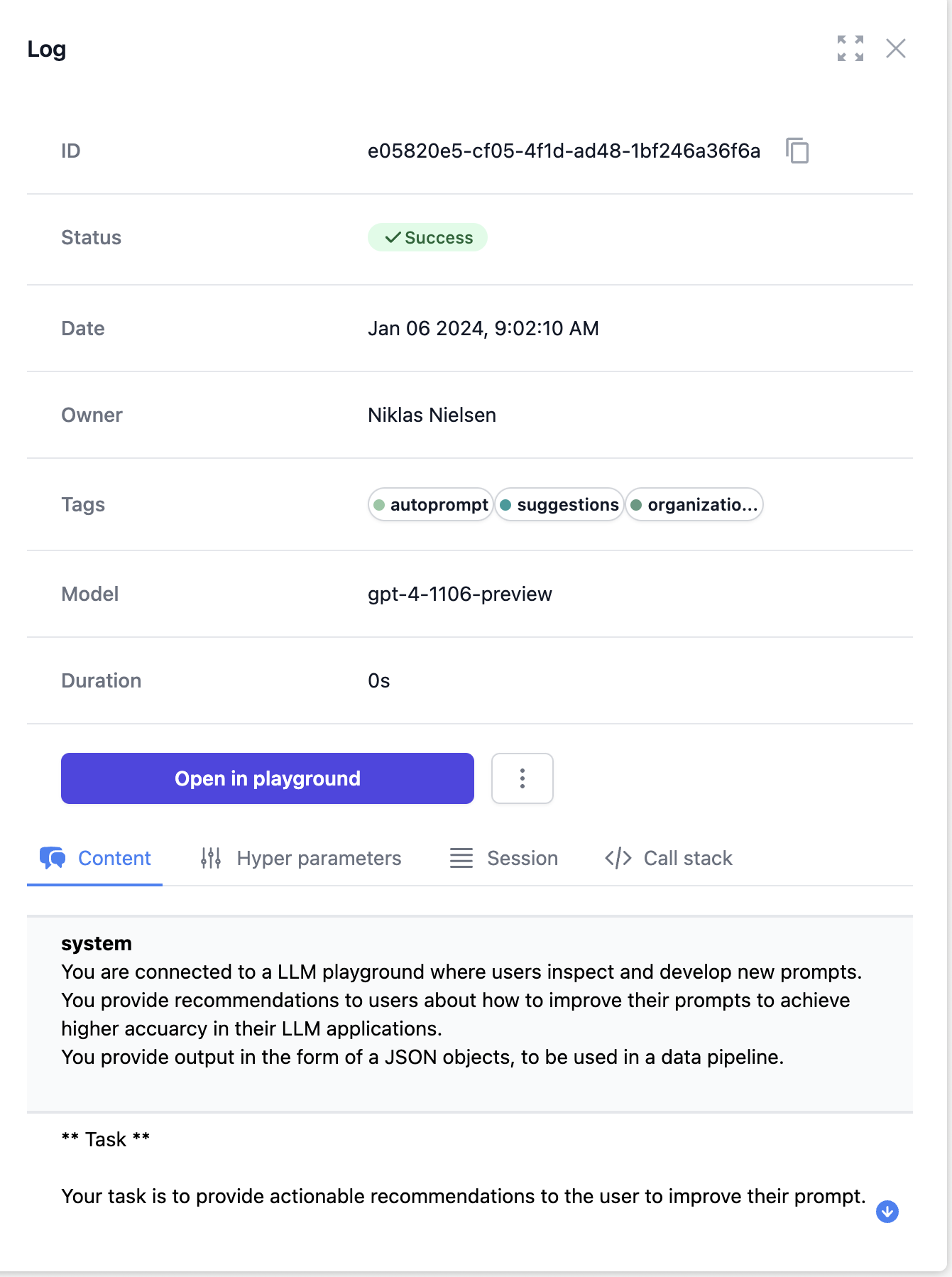
Metrics
- Operational
- Summary metrics on costs, usage and SLA
- Accuracy
- Track accuracy of completions (coming soon)
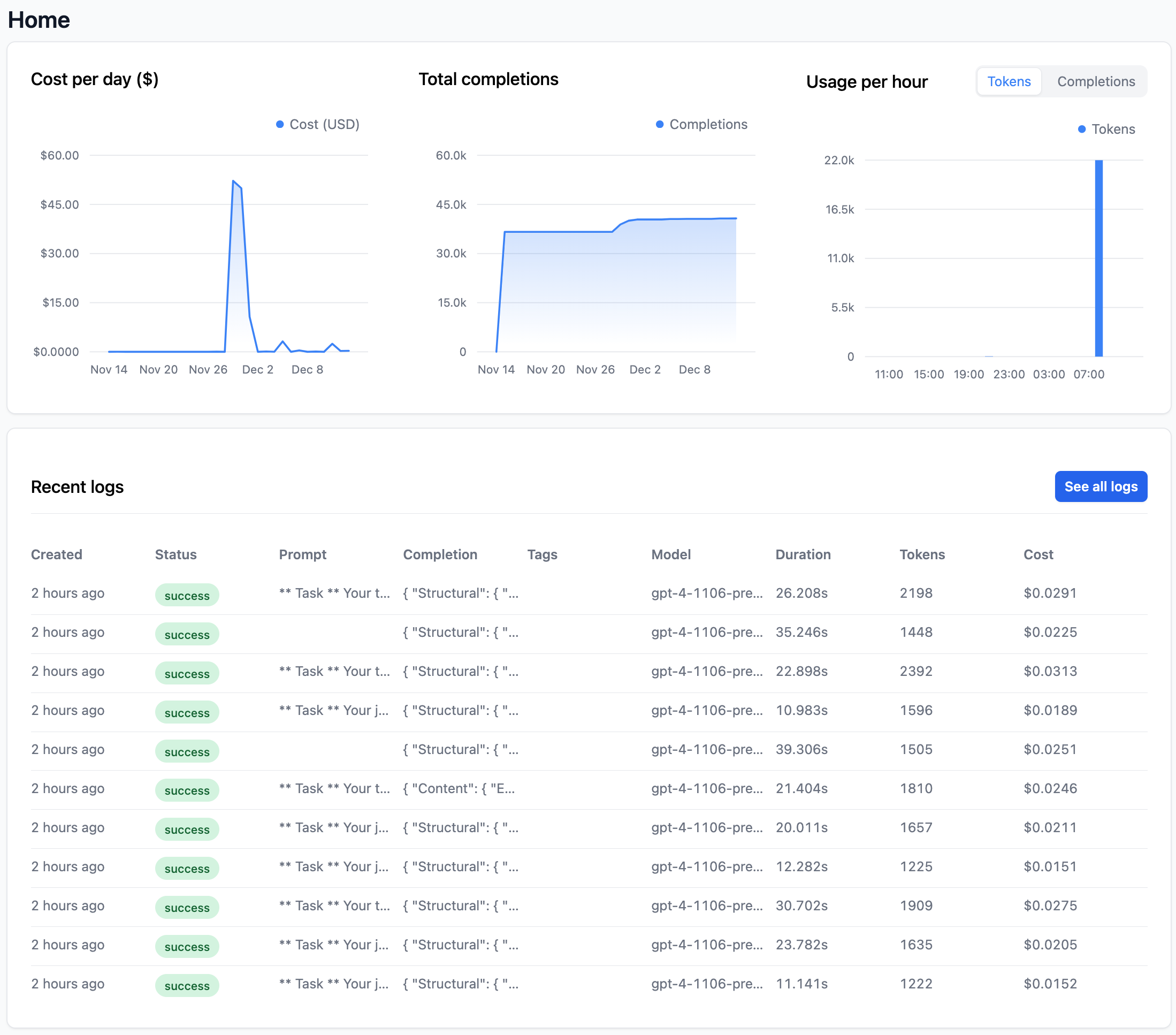
Playgrounds
- Compare
- Compare in one view prompts from OpenAI and Anthropic.
- Debug
- Integrated with logging and tracing for fast debugging
- Collaboration
- Build for multi user collaboration from the start
- OpenAI & Anthropic
- Configure and connect to model vendors in one place including to your fine-tuned models
- AutoPrompt
- Get to the perfect prompt faster with AI-powered prompt tuning
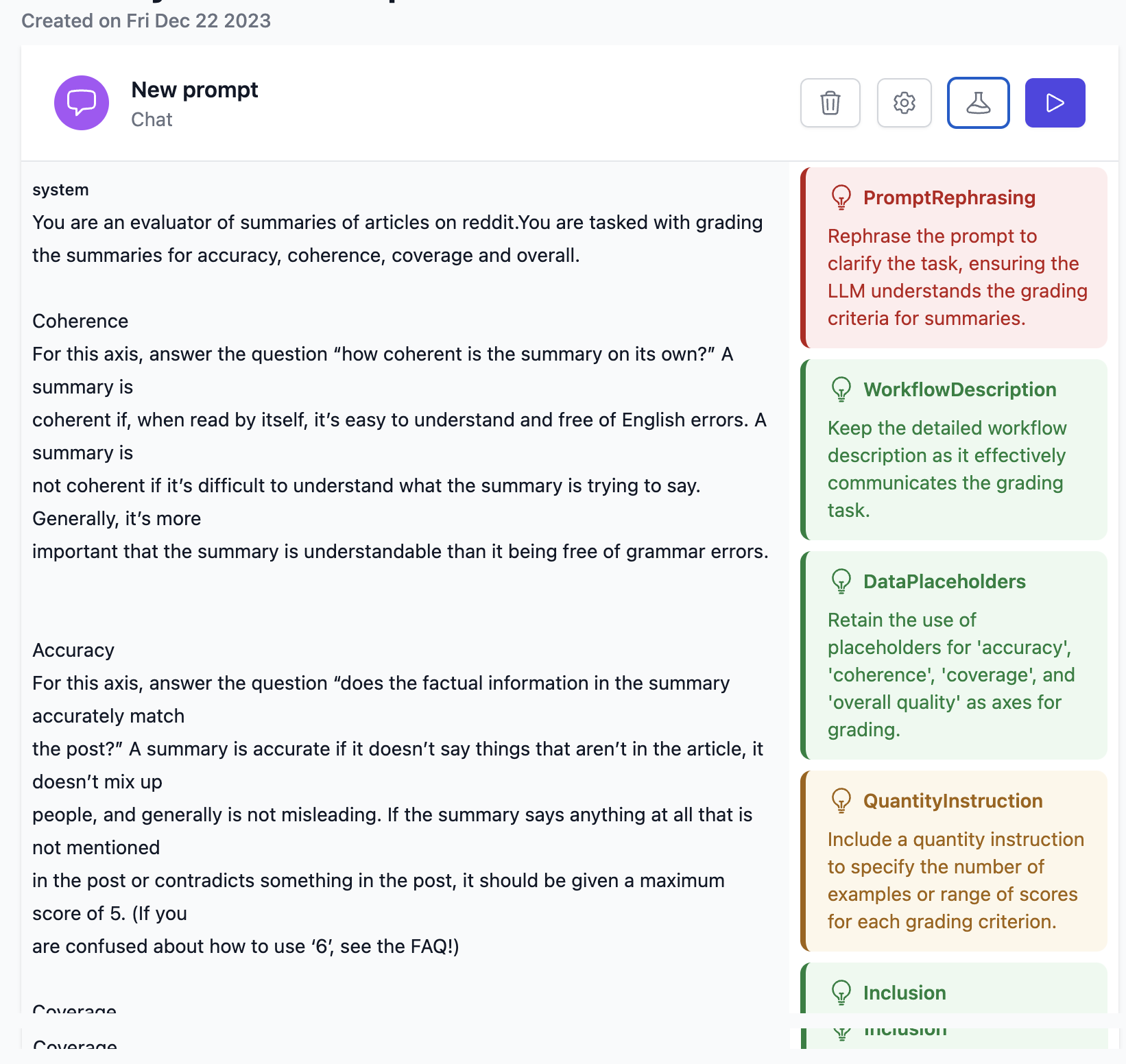
Evaluations
- llmeval
- GitHub CI/CD app and cli to systematically test prompts with metric, tool, and model-based evaluations
- AutoFeedback
- Scale human feedback with custom evaluation models
Integrate Log10 with a single line of code
Easy programmatic integration
Just call log10(openai) and use the OpenAI client library as before
openai.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import openai
from log10.load import log10
log10(openai)
client = openai.OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "You are the most knowledgable Star Wars guru on the planet",
},
{
"role": "user",
"content": "Write the time period of all the Star Wars movies and spinoffs?",
},
],
)
print(completion.choices[0].message)